

Labeling and Crowdsourcing
Introduction by



Michael Bernstein
Michael Bernstein is an Associate Professor of Computer Science and STMicroelectronics Faculty Scholar at Stanford University, where he is a member of the Human-Computer Interaction Group. His research focuses on the design of social computing systems. This research has won best paper awards at top conferences in human-computer interaction, including CHI, CSCW, and UIST. Michael has been recognized with an NSF CAREER award, Alfred P. Sloan Fellowship, UIST Lasting Impact Award, and the Patrick J. McGovern Tech for Humanity Prize.
Crowdsourced data annotation has shifted from a curiosity to an industry. By recruiting ghost workers from global platforms such as Amazon Mechanical Turk, Appen, and Upwork, product teams now annotate massive volumes of data to train their models. Despite this growth—and in many ways because of this growth—the systemic issues with crowdsourced data annotation continue to torment researchers, product teams, and workers alike. Wages are lost, annotations are tossed. What are you to do, if your goal is an annotated dataset?
Many of these issues boil down to a mistaken belief that data annotation can be entirely hands off.
Many of these issues boil down to a mistaken belief that data annotation can be entirely hands off: that our instructions are perfect conveyors of our intent. When we believe that the task is “so simple!”, it prompts people to get upset by data that comes back messy and workers to be frustrated at the task that is, inevitably, not as simple as it seems.
Let’s take an example, the supposedly simple task of labeling whether an online comment is toxic. This task is the foundation of Google’s Perspective API.


As my collaborators at Stanford and I found, this comment splits the jury: roughly half of annotators think that it crosses the line, and half don’t. So the task is easy to describe, but the challenge is all in the particulars. What does it mean, precisely, to cross the line? Whose voices should matter in making this determination?
Ultimately, every task is like this in one way or another. Asking a worker to perform an annotation task, such as labeling an image with text or classifying it into a certain category, may seem like a simple task, but the huge multiplicity of different interpretations can adversely affect the quality of data generated by crowdworkers. It’s like we’re forgetting the lessons of the past.
If you are someone hoping to utilize crowdsourcing in their machine learning project, how should you go about annotating your data? I’m not here to say that data annotation is impossible. But, as someone who has seen the highs and lows of crowdsourcing data annotation, I can say: a mindset shift can save both you and the annotators a ton of pain. This is ultimately a problem that entails—amongst other things—user interface design, where you take the concept of how you want people to label your data, and translate it into a concrete design where people will understand what you are asking them to do. Problems are much more typically reflective of a breakdown in your interface, in your instructions, and in your collaborative relationship, than they are of any sort of malfeasance or lack of skill.
There are two major challenges to this goal: one, task designers often assume that their instructions are clear, when in fact they’re not. Even professional designers aren’t great at communicating this clarity, and if professional designers struggle, it should put into perspective the difficulty of what machine learning engineers, as non-professional designers, are attempting to do. Plus, we often overestimate how clearly we convey our intent online. Second, the concepts task designers are trying to communicate to the workers are often not fully formed. At first, your idea of how to label something may seem clear, but when you actually start looking at some of the edge cases, there are multiple perfectly reasonable interpretations of how to annotate difficult cases.
So, here are some concrete steps that I take.
First, label many of the examples yourself before designing the task.
Second, pay and treat your workers fairly.
‘Nuff said. Data annotation is not a viable job for many workers. Most popular crowdsourcing platforms such as Amazon Mechanical Turk (AMT) do not enforce a minimum wage and do not offer workers the bundle of protections that tend to be attached to full-time employment. If this were a moral issue only, it would be enough. But researchers have also documented how these harms rebound on the product team, for example how a culture of work rejection leads workers to become extremely conservative about the tasks they take on and avoid the toughest labeling cases. Speaking as a computer scientist, I would argue that the harms of these platforms stifle innovation: many creative thinkers avoid data annotation platforms when these platforms do more harm than good. Solutions here will require both design and regulation. We have to ask ourselves: what would it take to create platforms that many more workers would prefer to their existing jobs?


Third, always start with small pilots.
People often make a labeling task and then immediately launch it. Instead, start by having a colleague or a coworker test your taks out first. Launch your task to a small number of people before you start to scale your task up. There’s a classic result in Human Computer Interaction by Jacob Nielsen that shows that the vast majority of usability bugs in an interface can be caught by five to seven people. By piloting your labeling task—first on yourself, then on a few coworkers, then with a few workers who can give you feedback, and so on—you can catch surprising qualities about your task early on and give yourself the chance to iterate. Iterating on your task design can help reduce headaches, as well as improve your dataset and your model.
Fourth, always assume that the annotators are trying hard to build a model of your intentions: when something goes wrong, your reaction should be “what did I do wrong in communicating my intent?”, not “why weren’t they paying attention?”
It’s human psychology to try and fill in blanks in instructions. In the face of annotated data that doesn’t look the way you expect it should, your first response should be to ask, “What did I do wrong in communicating the instructions in my design?”, instead of assuming that the errors are due to workers’ mistakes. A common mistake task designers often make is assuming the worker is trying to scam the system by randomly answering as many questions as they can. In general, scammers are few in number and can be detected, whereas misunderstandings and lack of clarity are ubiquitous. A good practice is to assume the best of your annotators and rely on feedback from the workers to iterate and improve your task design.
Fifth, train with feedback.
Before you launch, there should always be a stage in your task design where annotators are exposed to the kinds of tasks they’ll be performing. The first generation of crowdsourcing used this as a filter, but it turns out to be far more effective if you give incremental feedback after every training item (“Right!”, “Actually, the answer was ___, and here’s why: […]”).
Sixth, it can often make sense to hire fewer people, more full time.
I find that you will often get more mileage out of working with a smaller set of annotators and training them with an open line of communication, than trying to recruit a giant crowd of annotators with a monolithic task design that works for everyone. Some crowdsourcing platforms, including at large tech companies, have foremen who help navigate this process. This is not a common strategy, which I think derives from the general proclivity of engineers to see it as “labels as a service” rather than hiring workers. In most crowdsourcing tasks, a small proportion of the workers do most of the work anyway, so it really is worth your time to identify a small number of annotators and work with them.
There are a couple projects that I was working on where using these techniques could have saved us a lot of time and engineering effort.
There are a couple projects that I was working on where using these techniques could have saved us a lot of time and engineering effort. One example was a project called HYPE that appeared at NeurIPS 2019, which was led by Stanford PhD students Sharon Zhou and Mitchell Gordon. The goal was to get a precise estimate of how often people were confusing GAN images for real images. Despite having worked in the crowdsourcing space for years, we just could not get the error bars on our results to be tight. We ended up drawing on a combination of many of the techniques above called Gated Instruction, which finally allowed us to measure the qualities we were interested in. I now point to Gated Instruction as being table stakes for any serious data annotation effort.
Another example is a project called Visual Genome, led by Professor Ranjay Krishna, who was co-advised by me and Professor Fei-Fei Li at Stanford. With Visual Genome, our goal was to help enable computer vision to reason about images by creating dense webs of relationships visible in each image, which we called a scene graph.

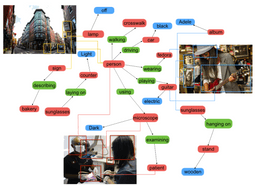
I’ll be honest: Visual Genome took years to really get off the ground. Creating scene graphs is extremely complex: labeling objects, labeling attributes on the objects, labeling relationships between those objects with attributes—and quality checking all of them. I almost blew out my faculty startup funds on this. We iterated and iterated. With the benefit of hindsight, I suspect that if we had implemented practices like Gated Instruction early on, or recruited some fulltime annotators off Upwork and trained them, we probably could have gotten a similar size and scale of data set with much less engineering effort. I believe the same could be said for datasets of similar scope and ambition. HYPE and Visual Genome are just two examples of projects that benefited, and could have benefited more, from these techniques.
These techniques are not magic. They’re not technical wizardry. What they are, and why they’re so counterintuitive for many folks in tech, is a mindshift away from “labels as a service” to “hiring collaborators”.
These techniques are not magic. They’re not technical wizardry. What they are, and why they’re so counterintuitive for many folks in tech, is a mindshift away from “labels as a service” to “hiring collaborators”. When you think of labels as a service, you assume any errors are the service breaking; when you think of hiring collaborators, you assume that it takes some training and relationship development. The end results are better for all involved.
















